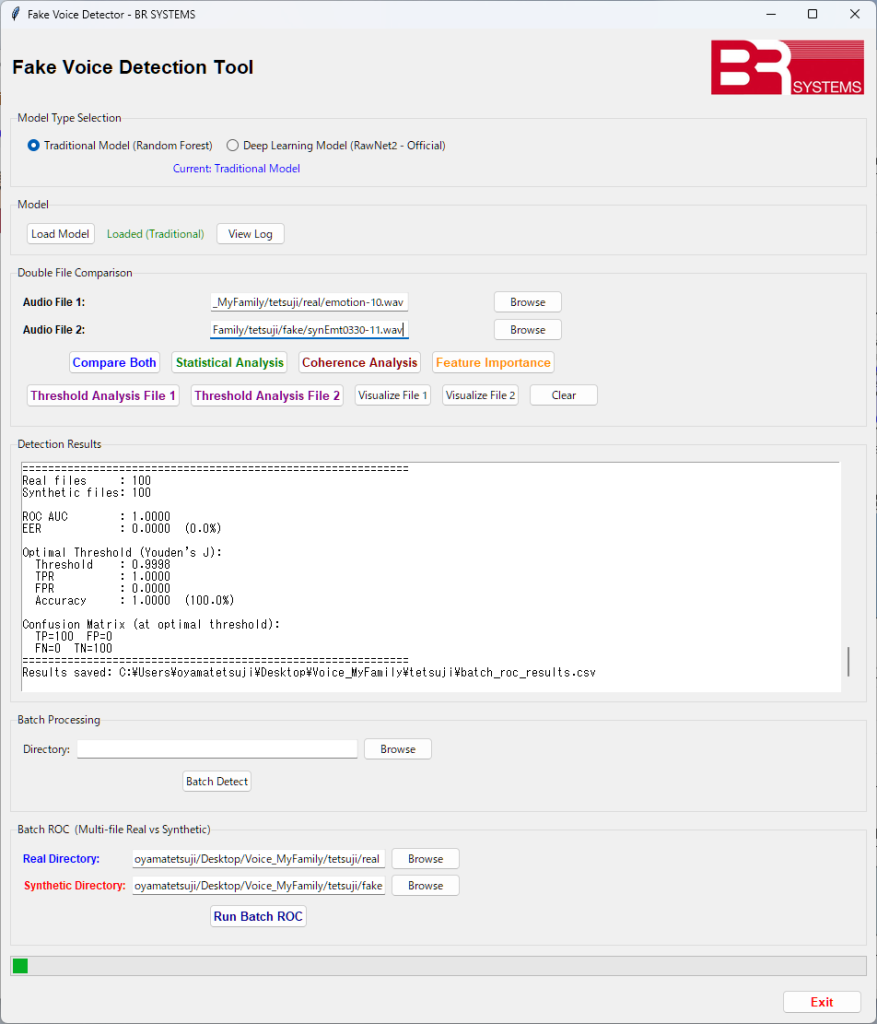
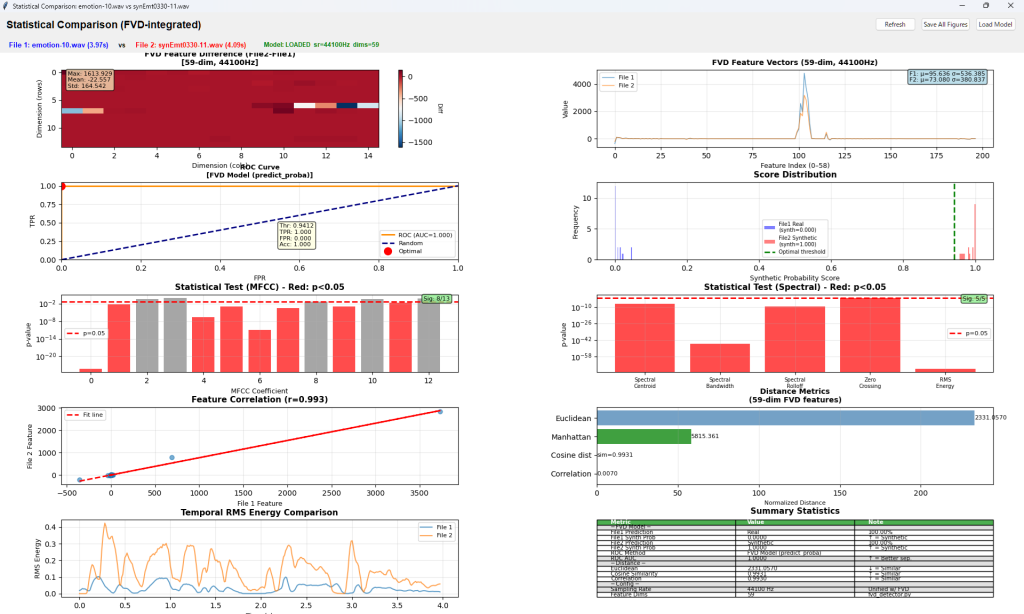
操作画面と出力例を示します。下記例は、Traditional Modelで個人特化フェイク音声検出(Personalized FVD)の例です。
使用例
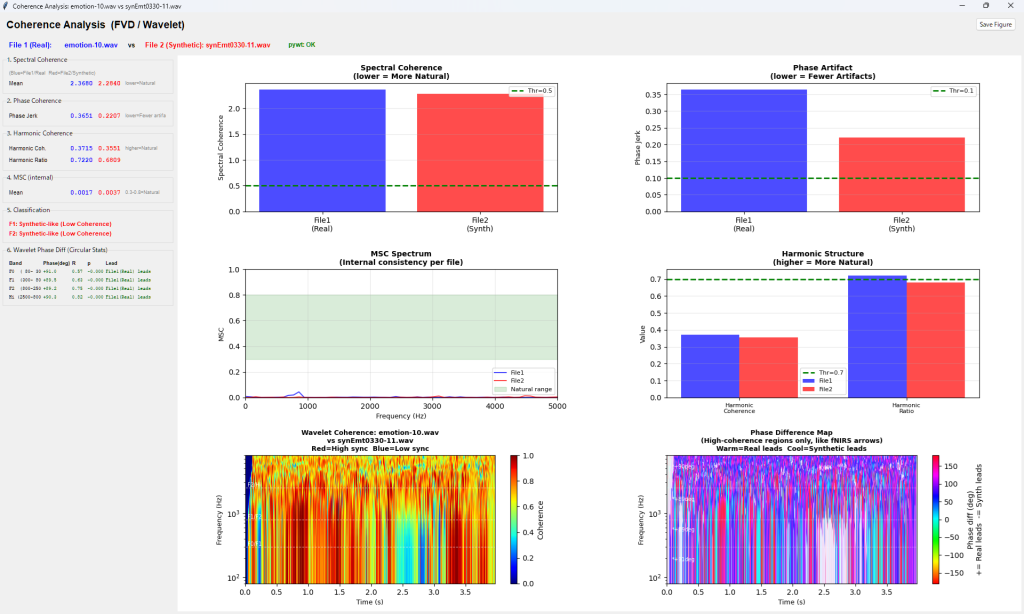
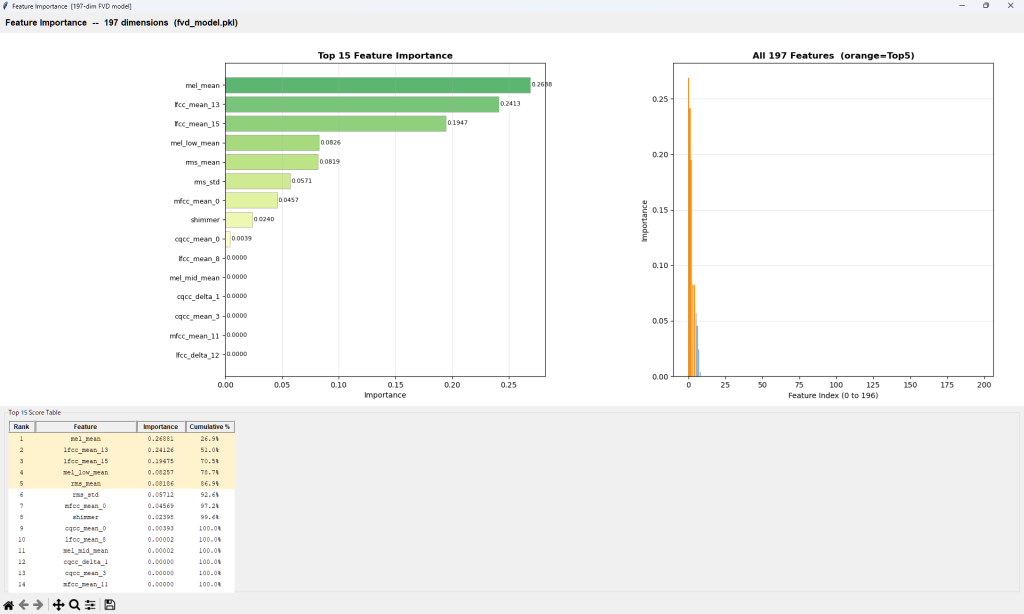
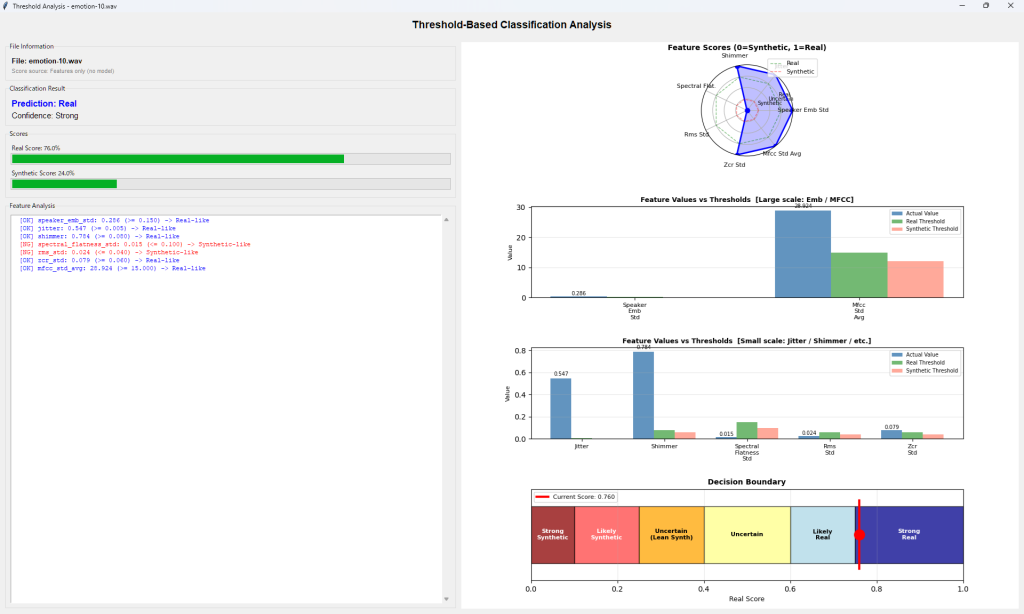
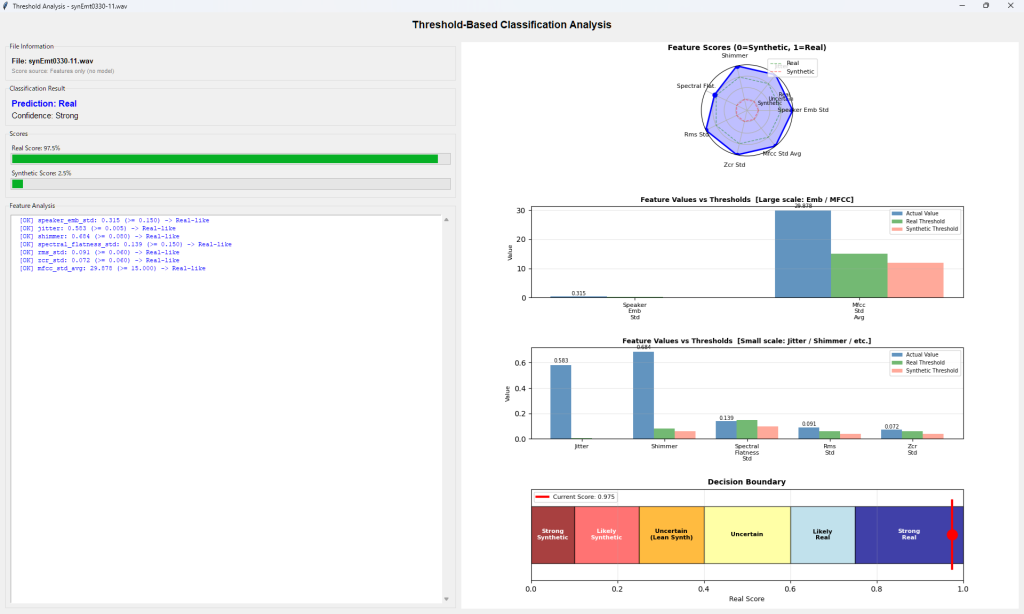
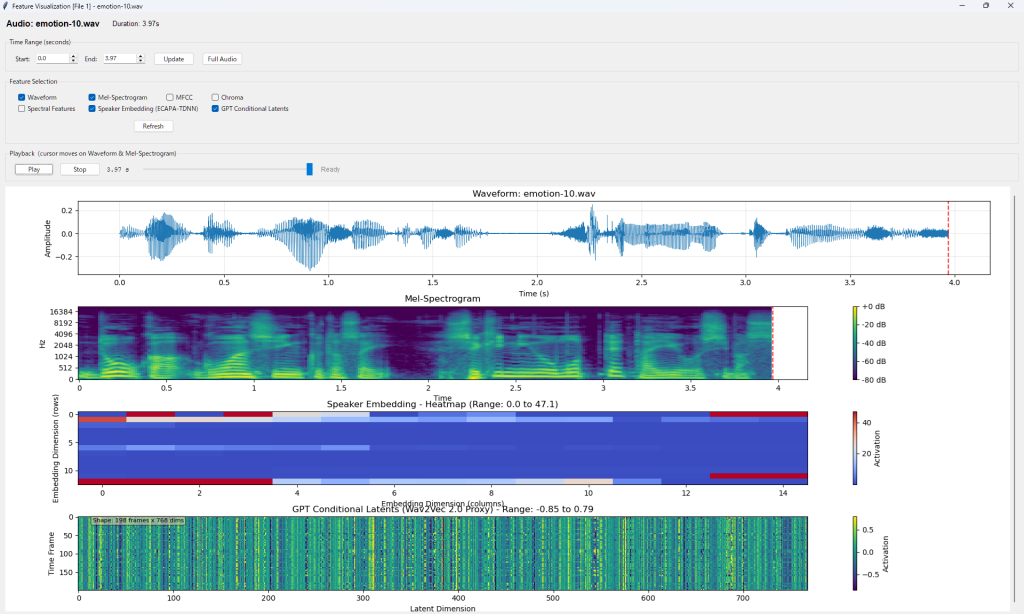
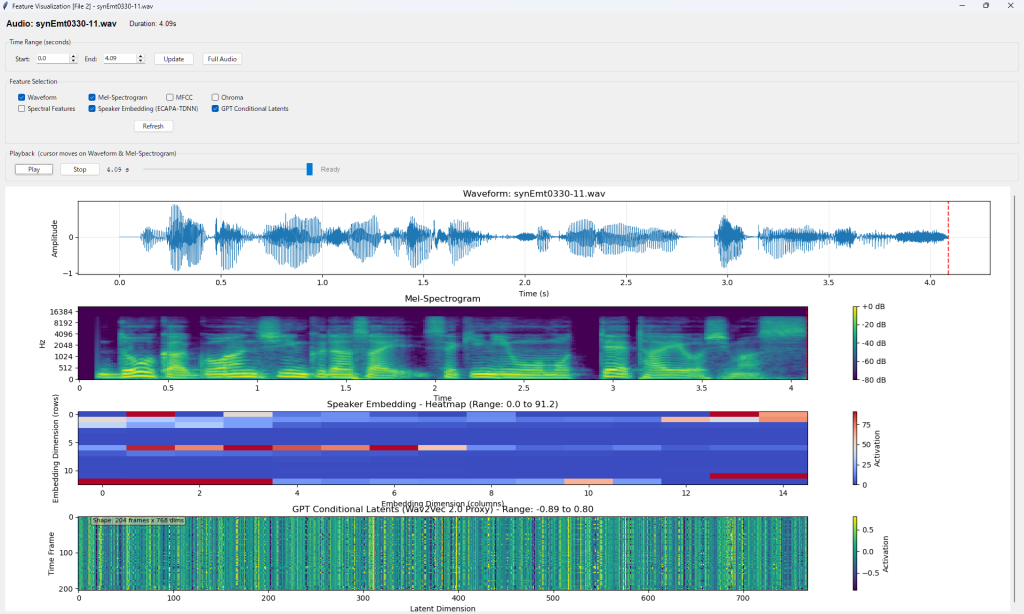
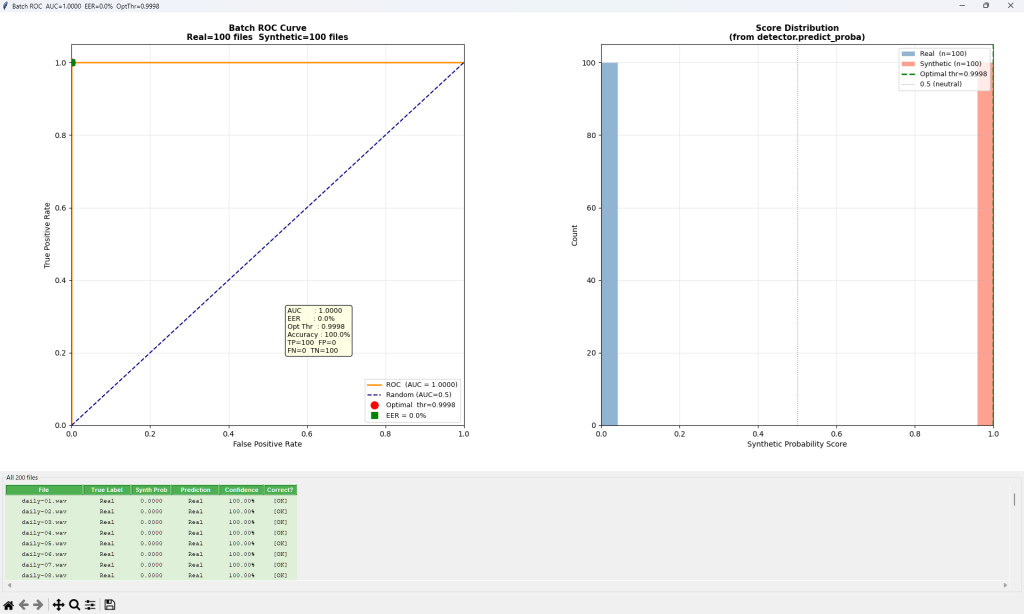
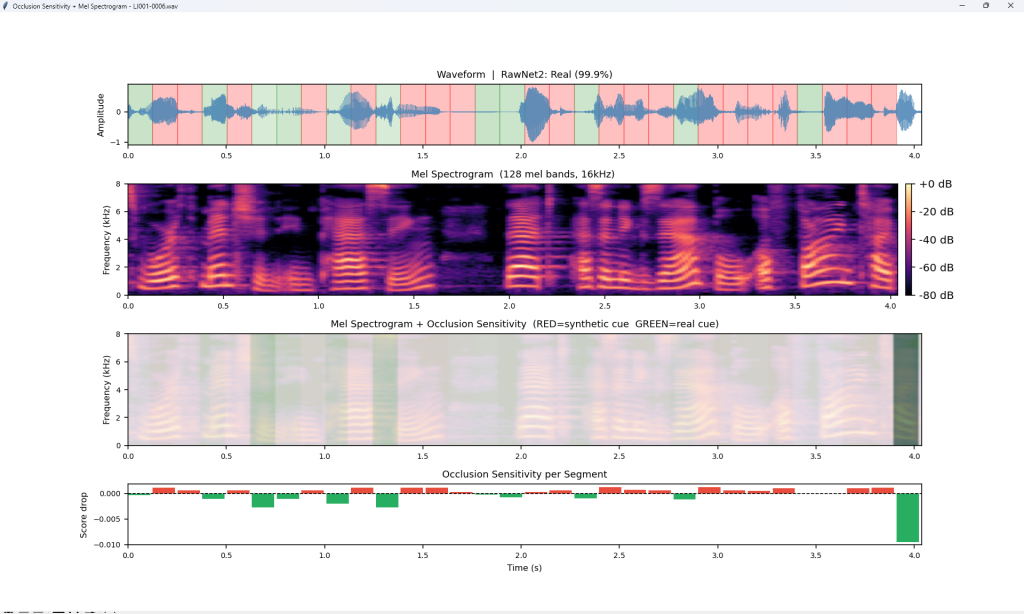
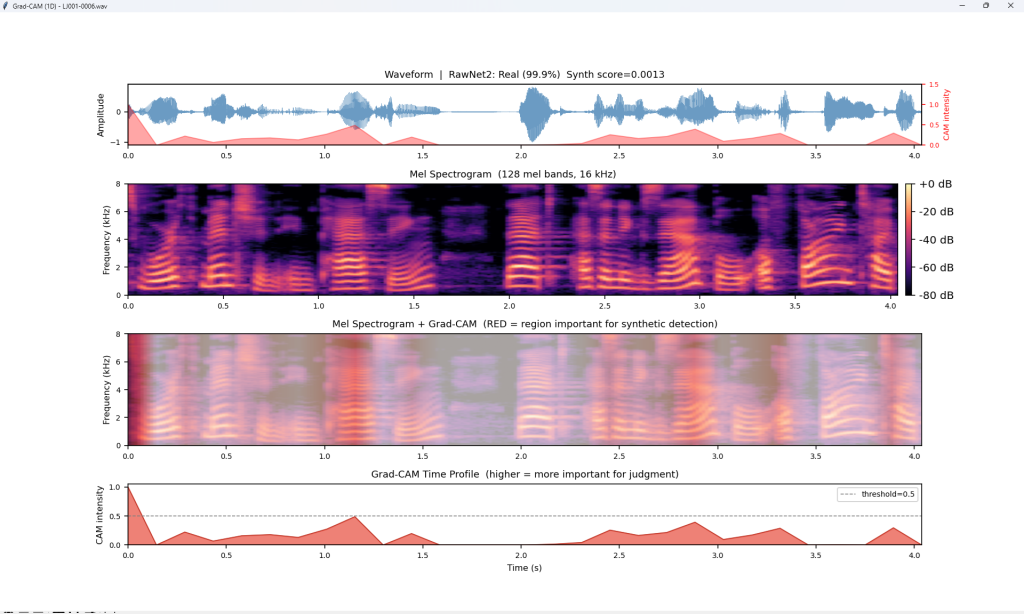
下記例は、Deep Learning Modelで汎用フェイク音声検出(Universal Fake Detection)のGrad-COMとOcclusion Sensitivityの例です。これらのツールは音声のどの領域(時間区間、周波数域)がreal/fakeの判定根拠となったかを視覚的に判別できます。RawNet2が検出しているのは、・SincConvフィルタの応答パターン,・子音母音遷移の自然さ,・無音区間の特性,・音声の微細な周期性,・呼吸声門閉鎖の痕跡 です。